Radio Galaxy Zoo
ATLAS cross-identification
This project is maintained by radiogalaxyzoo
Machine learning for radio source host galaxy cross-identification
M. J. Alger, J. K. Banfield, C. S. Ong, L. Rudnick, O. I. Wong, C. Wolf, H. Andernach, R. P. Norris, S. S. Shabala
submitted to Monthly Notices of the Royal Astronomical Society: day-month-year
Abstract
We consider the problem of determining the host galaxies of radio sources by cross-identification. This has traditionally been done by eye and expert judgement, a method that will be intractable for wide-area radio surveys like the Evolutionary Map of the Universe (EMU). Automated cross-identification will be critical for these future surveys, and machine learning may provide the tools to develop such methods. We apply a standard approach from computer vision to cross-identification, introducing one possible way of automating this problem, and explore the pros and cons of this approach. We apply our method to the 1.4 GHz Australian Telescope Large Area Survey (ATLAS) observations of the Chandra Deep Field South (CDFS) and the ESO Large Area ISO Survey South 1 (ELAIS-S1) fields by cross-identifying them with the Spitzer Wide-area Infrared Extragalactic (SWIRE) survey. We train our method with two sets of data: expert cross-identifications of CDFS from the initial ATLAS data release and crowdsourced cross-identifications of CDFS from Radio Galaxy Zoo. We found that a simple strategy of cross-identifying a radio component with the nearest galaxy performs comparably to our more complex machine learning methods, though our estimated best-case performance is near 100 per cent. ATLAS contains 87 complex radio sources that have been cross-identified by experts, so our method does not see enough complex examples to learn how to cross-identify them accurately. Much larger datasets are therefore required for training methods like ours. We also show that training our method on Radio Galaxy Zoo cross-identifications gives comparable results to training our method on expert cross-identifications, demonstrating the value of crowdsourced training data.
Appendix C: SWIRE Object Scores
In Table C1 and Table C2 we list the scores for each SWIRE infrared object in CDFS and ELAIS-S1 respectively.
- Table C1: Scores output by our trained classifiers for SWIRE CDFS candidate host galaxies.
- Table C2: Scores output by our trained classifiers for SWIRE ELAIS-S1 candidate host galaxies.
Appendix D: ATLAS Component Cross-identifications
In Table D1 and Table D2 we list the SWIRE cross-identifications of each ATLAS radio component in CDFS and ELAIS-S1 respectively.
- Table C1: Cross-identifications for ATLAS CDFS components.
- Table C2: Cross-identifications for ATLAS ELAIS-S1 components.
Appendix E: Cross-identification figures
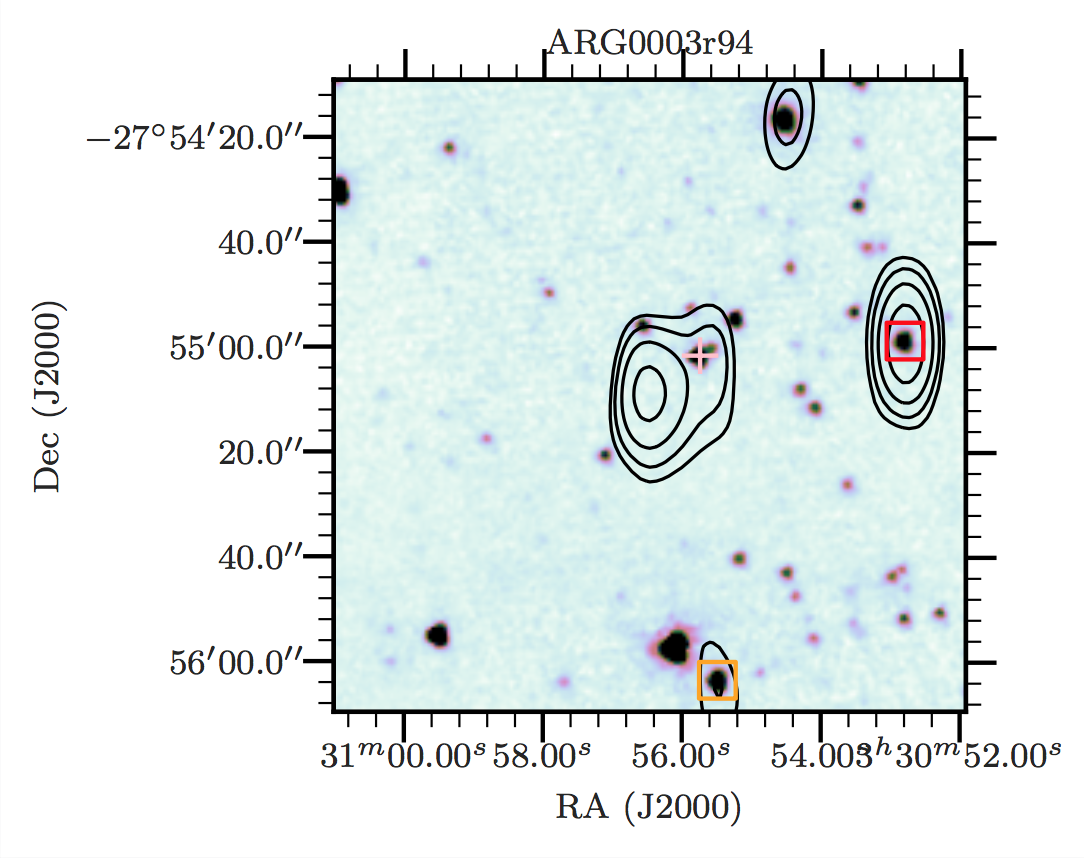
Figure E1 (a)–(ra) shows cross-identifications of resolved sources. As an example of the full set of figures, we show Figure E1(qy).
Figure E1(qy)
Running the Experiments
- Clone
chengsoonong/crowdastroandchengsoonong/crowdastro-projects. - Edit
crowdastro/crowdastro/crowdastro.jsonto point to the data files. Runpython3 -m crowdastro.import_data --ir swireto import the SWIRE and ATLAS datasets. This results incrowdastro.h5, and so can be skipped if you already have this file. - Run
crowdastro/notebooks/100_radio_table.ipynbto buildone-table-to-rule-them-all.tbl, which is a cross-identified table of the three ATLAS catalogues. - Edit
crowdastro-projects/scripts/pipeline.pyto point to the data paths, then run it. This produces all prediction and cross-identification output files.